
當您在修改其他變數時,將處理量繪製成隨時間變化的圖表,通常會看到處理量增加,直到處理量達到資源耗盡的程度為止。
下圖顯示典型的處理量資源調度圖表。隨著用戶端數量增加,工作負載和輸送量也會增加,直到所有資源耗盡為止。
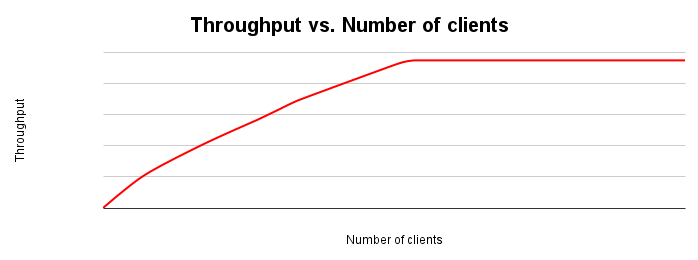
理想情況下,系統負載加倍時,處理量也應加倍。實際上,資源會發生爭用情形,導致總處理量增幅較小。資源耗盡或爭用會導致輸送量趨緩,甚至降低。如果您要盡量提高處理量,請務必找出這個關鍵點,因為這會決定您要調整應用程式或資料庫系統的哪個部分,才能提高處理量。
輸送量趨於平緩或下降的常見原因包括:
- 資料庫伺服器上的 CPU 資源耗盡
- 用戶端 CPU 資源耗盡,因此不會再將工作傳送至資料庫伺服器
- 資料庫鎖定爭用
- 資料超過 Postgres 緩衝區集區大小時的 I/O 等待時間
- 因儲存引擎使用率而導致的 I/O 等待時間
- 網路頻寬瓶頸會將資料傳回用戶端
延遲時間和輸送量成反比。延遲時間越長,總處理量就越低。直覺上來說,這很合理。當瓶頸開始成形,作業就會開始耗費更多時間,且系統每秒執行的作業也會減少。

延遲比例圖表顯示系統負載增加時,延遲的變化情形。延遲時間會維持相對恆定,直到資源爭用導致摩擦為止。這條曲線的轉折點通常對應於處理量縮放圖中的處理量曲線趨平。
評估延遲的另一種實用方式是使用直方圖。在這個表示法中,我們會將延遲時間分組到值區,並計算每個值區中的要求數量。

這個延遲時間直方圖顯示,大多數要求都在 100 毫秒內完成,且延遲時間超過 100 毫秒。瞭解延遲時間較長的要求原因,有助於說明應用程式效能的變化。延遲時間增加的長尾效應,與一般延遲時間縮放圖中延遲時間增加,以及輸送量圖趨於平緩的情況相符。
如果應用程式有多種模態,延遲直方圖就非常實用。模式是一組正常的運作條件。舉例來說,應用程式大部分時間都是存取緩衝區快取中的網頁。應用程式通常會更新現有資料列,但可能有多種模式。有時應用程式會從儲存空間擷取網頁、插入新資料列,或是發生鎖定爭用。
如果應用程式在一段時間內遇到這些不同的運作模式,延遲時間直方圖就會顯示這些多種模式。

這張圖顯示典型的雙峰直方圖,其中大部分要求都在 100 毫秒內完成服務,但另一組要求則需要 401 到 500 毫秒。瞭解第二種模態的原因,有助於提升應用程式效能。也可以有超過兩種模式。
第二種模式可能是因為正常的資料庫作業、異質基礎架構和拓撲,或是應用程式行為。以下列舉幾個例子:
- 大部分資料存取作業都是從 PostgreSQL 緩衝區集區進行,但有些作業是從儲存空間進行
- 部分用戶端連線至資料庫伺服器的網路延遲時間不同
- 應用程式邏輯,會根據輸入內容或一天中的時間執行不同作業
- 偶發鎖定爭用
- 用戶端活動量暴增