
שיטות מומלצות להתאמת קנה מידה של Cloud Service Mesh ב-GKE
במדריך הזה מתוארות שיטות מומלצות לפתרון בעיות שקשורות לשינוי גודל בארכיטקטורות מנוהלות של Cloud Service Mesh ב-Google Kubernetes Engine. המטרה העיקרית של ההמלצות האלה היא להבטיח ביצועים אופטימליים, אמינות וניצול משאבים של אפליקציות המיקרו-שירותים שלכם כשהן גדלות.
כדי להבין את המגבלות על יכולת ההתאמה לגודל, אפשר לעיין במאמר מגבלות על יכולת ההתאמה לגודל של Cloud Service Mesh
היכולת של Cloud Service Mesh להתרחב ב-GKE תלויה בפעולה היעילה של שני הרכיבים העיקריים שלו: מישור הנתונים ומישור הבקרה. המאמר הזה מתמקד בעיקר בהרחבת מישור הנתונים.
זיהוי בעיות בהרחבת מישור הבקרה לעומת מישור הנתונים
ב-Cloud Service Mesh, בעיות שקשורות לשינוי גודל יכולות להתרחש במישור הבקרה או במישור הנתונים. כך אפשר לזהות את סוג בעיית ההתאמה שנתקלים בה:
תסמינים של בעיות בהרחבת מישור הבקרה
גילוי שירותים איטי: לוקח הרבה זמן עד שמערכת מגלה שירותים או נקודות קצה חדשים והם הופכים לזמינים.
עיכובים בהגדרות: חולף זמן רב עד ששינויים בכללי ניהול התעבורה או במדיניות האבטחה מופצים.
עלייה בחביון בפעולות של רמת הבקרה: פעולות כמו יצירה, עדכון או מחיקה של משאבי Cloud Service Mesh הופכות לאיטיות או לא מגיבות.
שגיאות שקשורות ל-Traffic Director: יכול להיות שתראו שגיאות ביומנים של Cloud Service Mesh או במדדים של מישור הבקרה שמצביעות על בעיות בקישוריות, על מיצוי משאבים או על הגבלת קצב של API.
היקף ההשפעה: בעיות במישור הבקרה משפיעות בדרך כלל על כל הרשת, וגורמות לירידה נרחבת בביצועים.
תסמינים של בעיות בהרחבת מישור הנתונים
עלייה בזמן האחזור בתקשורת בין שירותים: בקשות לשירות בתוך הרשת סובלות מזמן אחזור גבוה יותר או מזמן קצוב לתפוגה, אבל אין עלייה בשימוש במעבד (CPU) או בשימוש בזיכרון במאגרי השירות.
שימוש גבוה ב-CPU או בזיכרון בשרתי proxy של Envoy: שימוש גבוה ב-CPU או בזיכרון עשוי להצביע על כך ששרתי ה-proxy מתקשים להתמודד עם עומס התנועה.
השפעה מקומית: בעיות במישור הנתונים משפיעות בדרך כלל על שירותים או על עומסי עבודה ספציפיים, בהתאם לדפוסי התנועה ולניצול המשאבים של שרתי ה-proxy של Envoy.
שינוי קנה המידה של מישור הנתונים
כדי להרחיב את מישור הנתונים, אפשר לנסות את הטכניקות הבאות:
הגדרת התאמה אופקית של קבוצות Pod לעומס (HPA) לעומסי עבודה
אפשר להשתמש ב-Horizontal Pod Autoscaling (HPA) כדי לשנות את גודל עומסי העבודה באופן דינמי באמצעות קבוצות Pod נוספות על סמך ניצול המשאבים. כשמגדירים HPA, כדאי להביא בחשבון את הנקודות הבאות:
משתמשים בפרמטר
--horizontal-pod-autoscaler-sync-periodtokube-controller-managerכדי לשנות את קצב הסקר של בקר ה-HPA. קצב הסקרים שמוגדר כברירת מחדל הוא כל 15 שניות, ואם אתם צופים עליות מהירות בתנועת הגולשים, כדאי להגדיר קצב נמוך יותר. למידע נוסף על מקרים שבהם כדאי להשתמש ב-HPA עם GKE, אפשר לקרוא את המאמר התאמה אופקית של קבוצות Pod לעומס.התנהגות ברירת המחדל של שינוי הגודל יכולה לגרום לפריסה (או לסיום) של מספר גדול של פודים בבת אחת, מה שעלול לגרום לעלייה חדה בשימוש במשאבים. כדאי להשתמש בכללי מדיניות של שינוי גודל כדי להגביל את קצב הפריסה של הפודים.
כדי למנוע ניתוקים במהלך צמצום הקיבולת, משתמשים ב-EXIT_ON_ZERO_ACTIVE_CONNECTIONS.
לפרטים נוספים על HPA, אפשר לעיין במאמר בנושא התאמה אופקית של קבוצות Pod לעומס במסמכי העזרה של Kubernetes.
אופטימיזציה של הגדרת Envoy Proxy
כדי לבצע אופטימיזציה של ההגדרה של Envoy proxy, כדאי לפעול לפי ההמלצות הבאות:
מגבלות על משאבים
אתם יכולים להגדיר בקשות למשאבים ומגבלות עבור Envoy sidecars במפרט של ה-Pod. כך נמנעת תחרות על משאבים ומתקבלים ביצועים עקביים.
אפשר גם להגדיר מגבלות ברירת מחדל על משאבים לכל שרתי ה-proxy של Envoy ברשת באמצעות הערות על משאבים.
מגבלות המשאבים האופטימליות עבור שרתי ה-proxy של Envoy תלויות בגורמים כמו נפח התנועה, מורכבות עומס העבודה ומשאבי הצומת של GKE. חשוב לעקוב אחרי Service mesh ולבצע בה שינויים באופן שוטף כדי להבטיח ביצועים אופטימליים.
שיקול חשוב:
- איכות השירות (QoS): הגדרת בקשות ומגבלות מבטיחה שלשרתי ה-proxy של Envoy תהיה איכות שירות צפויה.
הגדרת היקף ליחסי תלות בין שירותים
כדאי לשקול לצמצם את גרף התלות של הרשת על ידי הצהרה על כל התלויות באמצעות Sidecar API. כך מגבילים את הגודל והמורכבות של ההגדרה שנשלחת לעומס עבודה מסוים, וזה חשוב במיוחד לרשתות גדולות יותר.
לדוגמה, התרשים הבא מציג את התנועה באפליקציית הדוגמה של חנות הבוטיק אונליין.
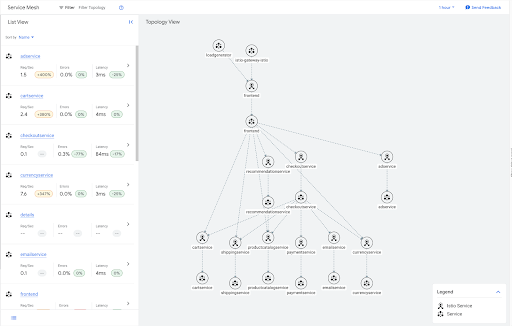
הרבה מהשירותים האלה הם עלים בגרף, ולכן הם לא צריכים לכלול מידע על תעבורת נתונים יוצאת (egress) מאף אחד מהשירותים האחרים ברשת. אפשר להחיל משאב Sidecar שמגביל את היקף ההגדרה של ה-Sidecar בשירותי העלים האלה, כמו בדוגמה הבאה.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
במאמר אפליקציית דוגמה של בוטיק אונליין מוסבר איך לפרוס את אפליקציית הדוגמה הזו.
יתרון נוסף של הגדרת היקף של קובץ sidecar הוא צמצום של שאילתות DNS מיותרות. הגדרת היקף של יחסי תלות בין שירותים מבטיחה ש-Envoy sidecar יבצע רק שאילתות DNS לשירותים שהוא יתקשר איתם בפועל, במקום לכל אשכול ב-Service mesh.
בכל פריסה רחבת היקף שבה יש בעיות עם גדלים גדולים של קובצי הגדרה ב-sidecar, מומלץ מאוד להגדיר את התלות בשירותים כדי לשפר את יכולת ההתאמה של הרשת.
מעקב וכוונון עדין
אחרי שמגדירים את מגבלות המשאבים הראשוניות, חשוב לעקוב אחרי שרתי ה-proxy של Envoy כדי לוודא שהם פועלים בצורה אופטימלית. אפשר להשתמש במרכזי הבקרה של GKE כדי לעקוב אחרי השימוש במעבד (CPU) ובשימוש בזיכרון, ולשנות את מגבלות המשאבים לפי הצורך.
כדי לקבוע אם שרת proxy של Envoy דורש הגדלה של מגבלות המשאבים, צריך לעקוב אחרי צריכת המשאבים שלו בתנאי תנועה רגילים ובתנאי תנועה בשיא. אלה הפרטים שצריך לחפש:
שימוש גבוה במעבד: אם השימוש במעבד של Envoy מתקרב באופן עקבי למגבלה או חורג ממנה, יכול להיות שהוא מתקשה לעבד בקשות, מה שמוביל לזמן אחזור מוגבר או לבקשות שנפסלות. כדאי להגדיל את מגבלת השימוש ביחידת העיבוד המרכזית (CPU).
במקרה כזה, יכול להיות שתחשבו על הגדלת הקיבולת באמצעות הרחבה אופקית, אבל אם שרת ה-proxy של ה-קובץ עזר חיצוני לא מצליח לעבד את הבקשות במהירות כמו קונטיינר האפליקציה, יכול להיות שהתאמה של מגבלות המעבד תניב את התוצאות הטובות ביותר.
שימוש גבוה בזיכרון: אם השימוש בזיכרון של Envoy מתקרב למגבלה או חורג ממנה, יכול להיות שהוא יתחיל להפיל חיבורים או יחווה שגיאות של חוסר זיכרון (OOM). כדי למנוע את הבעיות האלה, צריך להגדיל את מגבלת הזיכרון.
יומני שגיאות: בודקים ביומנים של Envoy אם יש שגיאות שקשורות לניצול יתר של משאבים, כמו השגיאות upstream connect error, disconnect or reset before headers או too many open files. יכול להיות שהשגיאות האלה מצביעות על כך שדרושים יותר משאבים לשרת הפרוקסי. במסמכים לפתרון בעיות שקשורות לשינוי גודל אפשר למצוא מידע על שגיאות אחרות שקשורות לשינוי גודל.
מדדי ביצועים: מעקב אחרי מדדי ביצועים מרכזיים כמו זמן האחזור של הבקשה, שיעורי השגיאות וקצב העברת הנתונים. אם אתם מבחינים בירידה בביצועים שקשורה לניצול גבוה של משאבים, יכול להיות שתצטרכו להגדיל את המגבלות.
הגדרת מגבלות על משאבים וניטור שלהן בשרתי proxy של מישור הנתונים מאפשרים לוודא שה-Service mesh תגדל ביעילות ב-GKE.
פיתוח חוסן
אפשר לשנות את ההגדרות הבאות כדי לשנות את קנה המידה של מישור הבקרה:
זיהוי חריגות
התכונה 'זיהוי חריגות' מנטרת את המארחים בשירות במעלה הזרם ומסירה אותם ממאגר איזון העומסים כשהם מגיעים לסף שגיאה מסוים.
- הגדרה מרכזית:
-
outlierDetection: הגדרות שקובעות את ההוצאה של מארחים לא תקינים ממאגר איזון העומסים.
-
- יתרונות: שומר על קבוצה תקינה של מארחים במאגר איזון העומסים.
מידע נוסף זמין במאמר בנושא זיהוי חריגות במסמכי Istio.
ניסיונות חוזרים
צמצום שגיאות זמניות על ידי ניסיון חוזר אוטומטי של בקשות שנכשלו.
- הגדרה מרכזית:
-
attempts: מספר הניסיונות החוזרים. -
perTryTimeout: הזמן הקצוב לתפוגה לכל ניסיון חוזר. הגדירו את משך הזמן הזה לקצר יותר ממשך הזמן הכולל להמתנה. הערך הזה קובע כמה זמן תמתינו לכל ניסיון חוזר. -
retryBudget: מספר הניסיונות החוזרים המקסימלי בו-זמנית.
-
- יתרונות: שיעורי הצלחה גבוהים יותר של בקשות, השפעה מופחתת של כשלים לסירוגין.
גורמים שכדאי לקחת בחשבון:
- אידמפוטנטיות: מוודאים שהפעולה שמנסים לבצע שוב היא אידמפוטנטית, כלומר אפשר לחזור עליה בלי תופעות לוואי לא רצויות.
- Max Retries: הגבלת מספר הניסיונות החוזרים (למשל, 3 ניסיונות חוזרים לכל היותר) כדי למנוע לולאות אינסופיות.
- Circuit Breaking: Integrate retries with circuit breakers to prevent retries when a service is consistently failing.
מידע נוסף מופיע במאמר Retries במסמכי התיעוד של Istio.
חסימות זמניות
משתמשים בערכי זמן קצוב לתפוגה כדי להגדיר את הזמן המקסימלי שמוקצב לעיבוד הבקשה.
- הגדרה מרכזית:
timeout: פסק זמן של בקשה לשירות ספציפי.-
idleTimeout: הזמן שחיבור יכול להישאר לא פעיל לפני שהוא נסגר.
- יתרונות: שיפור התגובה של המערכת, מניעת דליפות משאבים, הגנה מפני תנועה זדונית.
גורמים שכדאי לקחת בחשבון:
- השהיית רשת: צריך לקחת בחשבון את זמן הלוך ושוב (RTT) הצפוי בין השירותים. כדאי להשאיר מרווח ביטחון למקרה של עיכובים לא צפויים.
- גרף תלות בשירות: כדי למנוע כשלים מדורגים, צריך לוודא שזמן הקצוב לתפוגה של שירות שמבצע קריאה קצר יותר מזמן הקצוב לתפוגה המצטבר של התלויות שלו.
- סוגי פעולות: יכול להיות שיהיה צורך בערכי זמן קצובים (timeout) ארוכים יותר משמעותית למשימות ארוכות טווח מאשר לאחזור נתונים.
- טיפול בשגיאות: פסק זמן צריך להפעיל לוגיקה מתאימה לטיפול בשגיאות (למשל, ניסיון חוזר, חזרה למצב קודם, ניתוק מעגל).
מידע נוסף זמין במאמר בנושא Timeouts במסמכי התיעוד של Istio.
מעקב וכוונון עדין
כדאי להתחיל עם הגדרות ברירת המחדל של פסק זמן, זיהוי חריגים וניסיונות חוזרים, ואז לשנות אותן בהדרגה בהתאם לדרישות השירות הספציפיות ולדפוסי התנועה שנצפו. לדוגמה, אפשר לעיין בנתונים מהעולם האמיתי כדי לראות כמה זמן בדרך כלל לוקח לשירותים שלכם להגיב. לאחר מכן משנים את הגדרות הזמן הקצוב לתפוגה כך שיתאימו למאפיינים הספציפיים של כל שירות או נקודת קצה.
Telemetry
משתמשים בטלמטריה כדי לעקוב באופן רציף אחרי Service mesh ולשנות את ההגדרות שלו כדי לשפר את הביצועים והאמינות.
- מדדים: כדאי להשתמש במדדים מקיפים, ובמיוחד בנפחי בקשות, בחביון ובשיעורי שגיאות. שילוב עם Cloud Monitoring להצגה חזותית ולשליחת התראות.
- מעקב מבוזר: הפעלת שילוב של מעקב מבוזר עם Cloud Trace כדי לקבל תובנות מעמיקות לגבי זרימות הבקשות בשירותים שלכם.
- רישום ביומן: מגדירים רישום ביומן של גישה כדי לתעד מידע מפורט על בקשות ותגובות.
מקורות מידע נוספים
- מידע נוסף על Cloud Service Mesh זמין במאמר סקירה כללית של Cloud Service Mesh.
- הנחיות כלליות בנושא Site Reliability Engineering (SRE) לצורך שיפור יכולת ההתאמה לגודל זמינות בפרקים טיפול בעומס יתר וטיפול בכשלים מדורגים בספר Google SRE.